Utterance Templates
Utterance Templates
Utterance Templates provide you with precise control over your Parlant agent's responses.
By restricting to a predefined set of responses, you ensure your agent communicates with a consistent tone, style, and accuracy, aligning perfectly with your brand voice and service protocols while completely eliminating the risk of even subtle unwanted or hallucinated outputs.
Utterance templates function like a hand of cards: given a set of templates you provide to your agent, it selects the most appropriate "card" (template) that best matches the required response based on the conversation context.

Practical Example
Without Utterance Templates
Using LLM-generated (token-by-token) responses.
Customer: Do you have it in stock?
Agent: Yes, we've got this item in stock! Let me know if you need any help finding it.
With Utterance Templates
# Draft message: """
# Yes, we've got this item in stock! Let me know if you need any help finding it.
# """
#
# Available templates:
# - ...
# - "Hey, {{std.customer.name}}! What help do you need today?"
# - ...
# - "No, sorry, we've just sold the last ones. Would you like to see something similar?"
# - "Yep, we have it. Should I add it to your cart?"
# - ...
Customer: Do you have it in stock?
Agent: Yep, we have it. Should I add it to your cart?
How Utterance Templates Work
Under the hood, utterances templates work in a 3-stage process:
- The agent drafts a fluid message based on the current situational awareness (interaction, guidelines, tool results, etc.)
- Based on the draft message, it matches the closest utterance template found in your utterance store
- The engine renders the matched utterance template (which is in Jinja2 format), using tool-provided variable substitutions where applicable
Controlling the Draft Message
The best way to ensure that the right utterance template is selected is to ensure the draft message is generated as closely as possible to your desired utterance. This can be done using all of the regular control mechanisms such as guidelines, tools, glossary terms, and agent description.
Examining the Draft Message
You can inspect the draft message in the integrated UI to see what the agent attempted to say, given its guidelines.
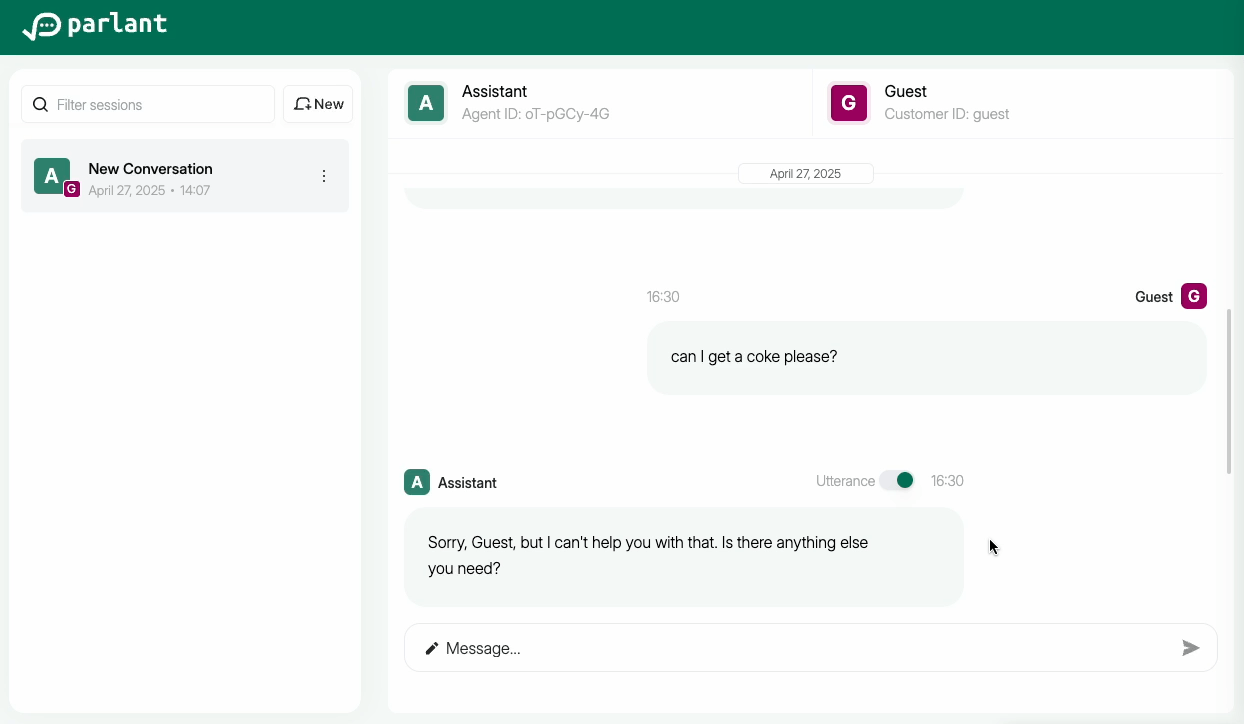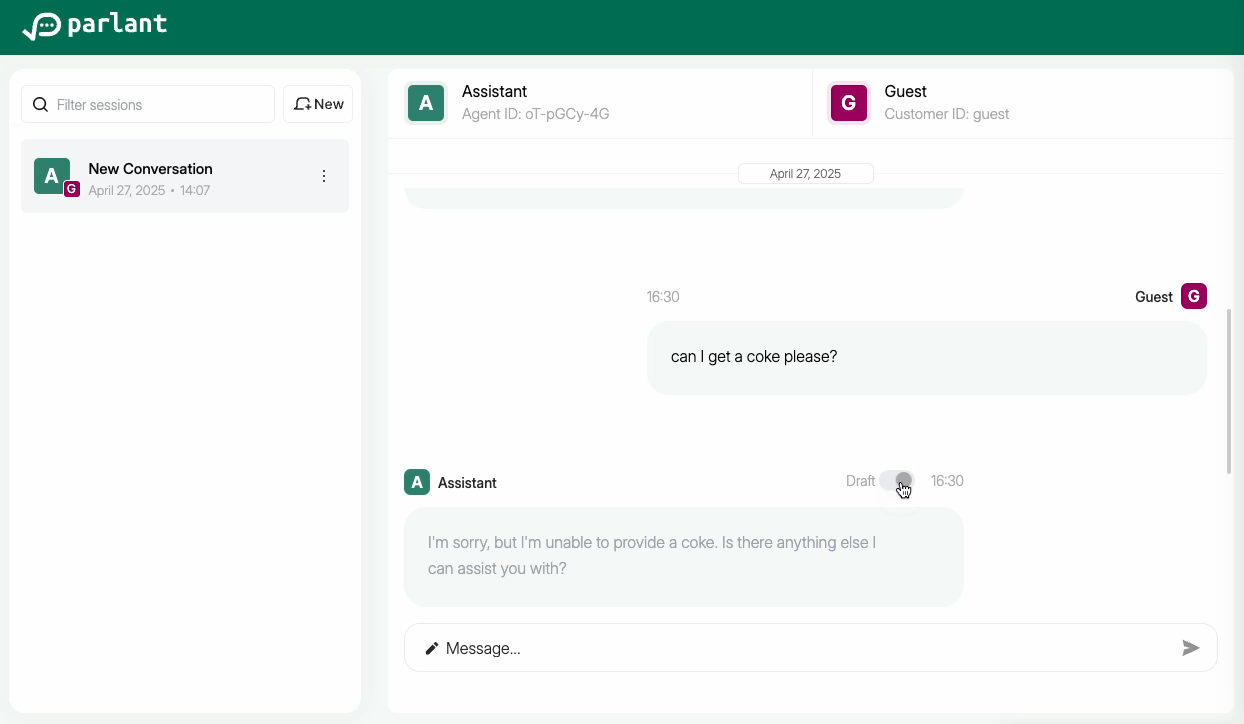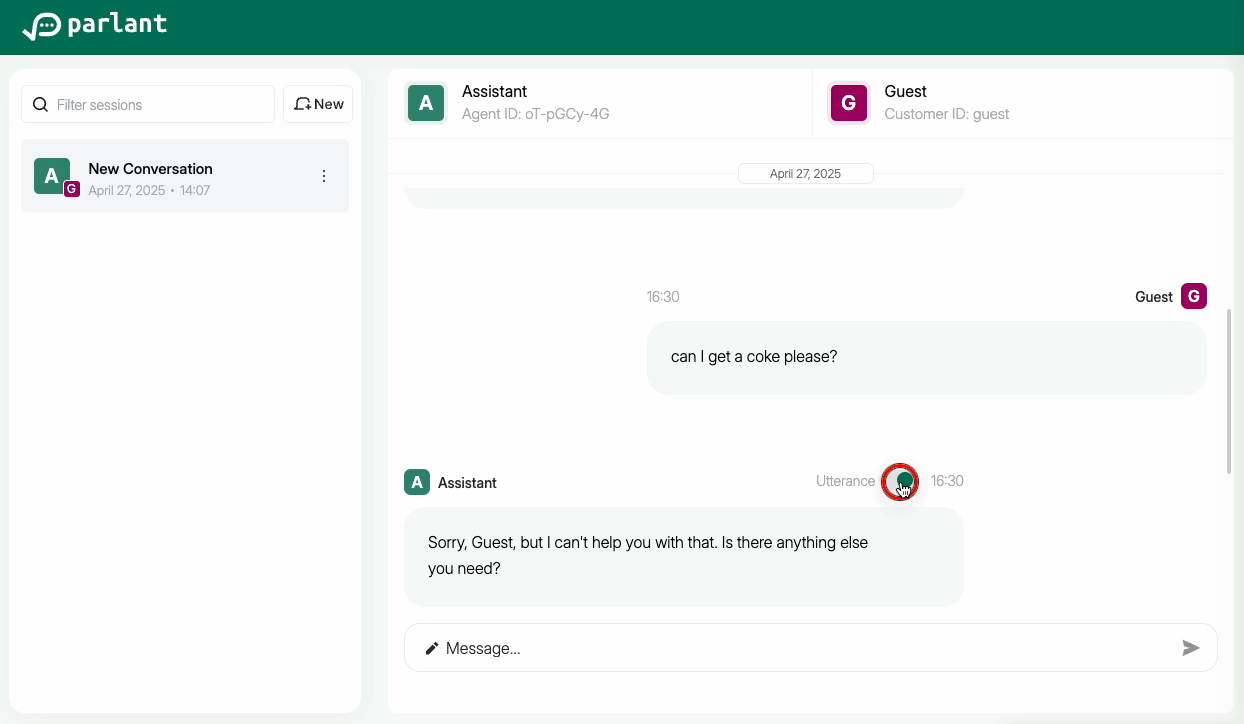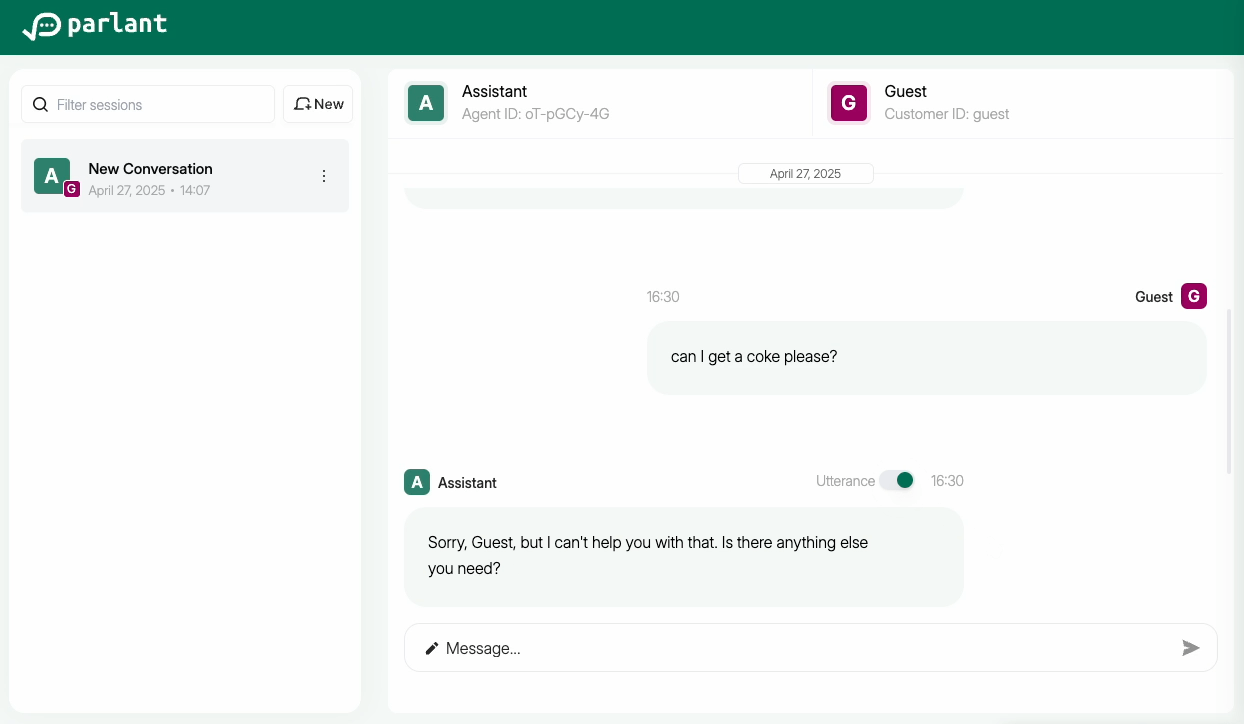
Enabling Utterances
Parlant agents can use one of several composition modes in their responses. These composition modes offer varying levels of restriction on the agent's outputs. To enable utterances, you must set your agent to use one of the following:
| Mode | Description | Use Cases |
|---|---|---|
| Strict Utterance | The agent can only select responses from the defined templates. If no matching template exists, the agent will send a customizable no-match message (this is being enhanced). | High-risk settings that cannot afford even the most subtle and infrequent hallucinations |
| Composited Utterance | Like strict utterance, but templates will be re-composed using an LLM to "massage" them into the conversation and add some natural variability. | Controlled settings where tone of voice is important to maintain |
| Fluid Utterance | The agent prioritizes selecting from templates if a match can be found, but may fall back to default message generation if no good match is found. | (A) Prototyping an agent, getting fluid recommendations for additional utterances as you go (B) Staying mostly fluid, but controlling specific situations and responses where applicable |
If you have a high-risk use case and are apprehensive about deploying GenAI agents to your customers, we recommend starting out with strict mode. Parlant is flexible and will allow you to easily transition to more fluid modes when you're ready. You will still maintain and utilize all other aspects of your conversation model as you switch between composition modes.
Setting an Agent's Composition Mode
When creating an agent:
parlant agent create \
--name $AGENT_NAME \
--description $AGENT_DESCRIPTION \
--composition-mode $COMPOSITION_MODE \ # [fluid|strict-utterance|composited-utterance|fluid-utterance]
--tag $TAG_ID
When updating an agent:
parlant agent update \
--id $AGENT_ID \
--composition-mode $COMPOSITION_MODE # [fluid|strict-utterance|composited-utterance|fluid-utterance]
Creating Utterance Templates
Currently, all of your utterance templates would be stored in a single, easily editable and version-tracked JSON file.
- Initialize a template file:
parlant utterance init YOUR_FILENAME.json
- Edit the generated JSON file with your custom utterances:
{
"utterances": [
{
"value": "Hello, {{std.customer.name}}!",
},
{
"value": "My name is {{std.agent.name}}"
}
]
}
- Load your templates to the Parlant server:
parlant utterance load YOUR_FILENAME.json
Template Syntax
Standard Variables
Use standard variables (using the std. prefix) to display dynamic information from the conversation context:
Available values
std.customer.name: String; The customer's name (orGuestfor a non-registered customer)std.agent.name: String; The agent's namestd.variables.NAME: Any; The content of a context variable namedNAMEstd.missing_params: List of strings; Contains the names of missing tool parameters (if any) based on Tool Insights
Example
{
"utterances": [
{
"value": "Hi {{std.customer.name}}, Yes, this product is available in stock."
}
]
}
Generative Variables
If you refer to a variable with a generative. prefix, the LLM will auto-infer and substitute the value based on its name and the surrounding context. This is a great way to introduce controlled, localized generation into strict templates.
Example
{
"utterances": [
{
"value": "Can I ask why you'd like to return {{generative.item_name}}?"
}
]
}
Tool-Based Variables
Utterance templates can refer to variables coming from tool results. These variables must be specified in the utterance_fields property of your tool's ToolResult. This is one of the most useful types of variables as they can introduce truly dynamic data into your utterances.
Example
@tool
def get_account_balance(context: ToolContext) -> ToolResult:
balance = 1234.5
return ToolResult(
# The data property is still important for fluid mode and for properly drafting the message
data={f"Account balance is {balance}"},
# Here you can specify dynamic values for template variable substitution
utterance_fields={"account_balance": balance},
)
{
"utterances": [
{
"value": "Your current balance is {{account_balance}}"
}
]
}
The Flexibility of Jinja2
Utterance templates integrate with the Jinja2 templating engine, enabling more dynamic formatting and list processing. You can learn more advanced syntax on the Jinja2 documentation site.
Example
@tool
def get_pizza_toppings(context: ToolContext) -> ToolResult:
toppings = ['olives', 'peppers', 'onions']
return ToolResult(
data={f"Toppings are {toppings}"},
utterance_fields={"toppings": toppings},
)
{
"utterances": [
{
"value": "We have the following toppings {% for topping in toppings %}\n- {{ topping }}{% endfor %}"
}
]
}